Our research areas
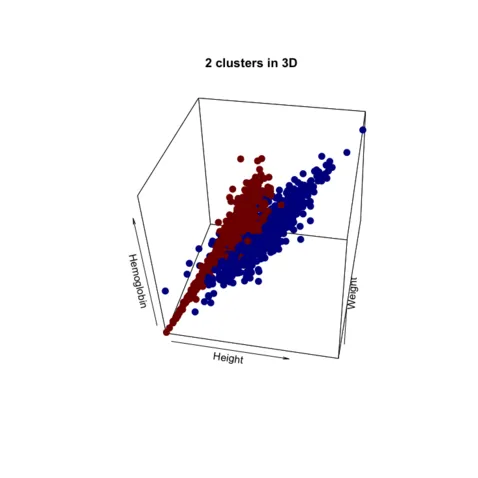
Model-based clustering with vine copulas
Members: Özge Sahin, Claudia Czado
Description: Finite mixture models are convenient statistical tools for model-based clustering. In this framework, one assumes that the data can be clustered using k components. The most prominent finite mixture model for continuous data is the mixture of multivariate Gaussian distributions (GMM). However, GMMs cannot accommodate the true shape of the non-elliptical components and model asymmetric dependencies within them. Since it is well known that vine copulas are very flexible in capturing dependencies, our main objective is to develop a vine copula mixture model and use it for model-based clustering, especially for the non-Gaussian data.
R package: vineclust [GitHub | Manual]
Results: [Article | Preprint | Presentation | Talk ]
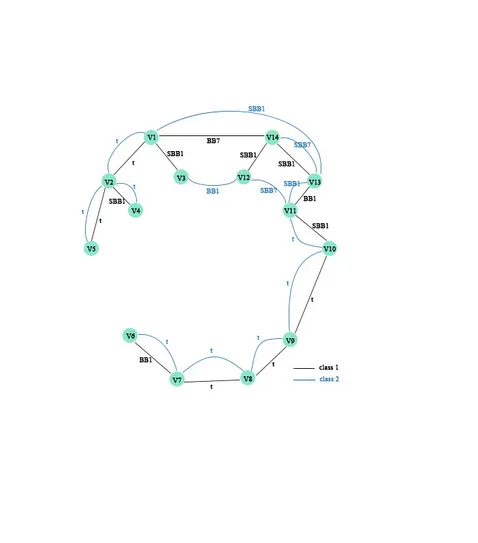
Vine copula-based classification approach for multivariate time series data
Members: Chunfang Zhang, Claudia Czado
Description: In applications we often observe multivariate time series exhibiting complex dependence structures as well as nonstationary behavior dependence. It is a difficult task to perform classification based on such multivariate time series data. We introduce a vine copula based approach to model such time series data. For this we use univariate nonstationary time series models for each time series to obtain approximately i.i.d. residuals. The dependence among the residuals are then captured by a vine copula. This approach is applied to each class and classification is now performed using a Bayes classifier. This approach will be applied to time series derived from a neural activity experiment to classify the opening and closing of the eyes. The performance to other classification methods will be investigated.
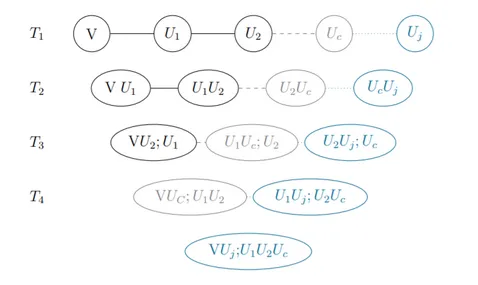
Statistical learning with vines for (quantile) regression
Members: Marija Tepegjozova, Claudia Czado
Description: Quantile regression is a field with growing importance for statistical modeling. It offers a more complete statistical model than mean regression and thus has widespread applications. We aim to develop a new method, that will overcome the usual drawbacks of the standard models, such as quantile crossings, distributional assumptions and misspecification of the tail dependencies. Our idea how to overcome such shortfalls, is to use vine copula based quantile regression. Vine-copulas allow for highly flexible modeling of high-dimensional dependence structures, and developing a vine based quantile regression with automated covariate selection procedure is the main research objective.
Results: [Article | Preprint | Presentation| Talk ]
Results - Bivariate: [Preprint]
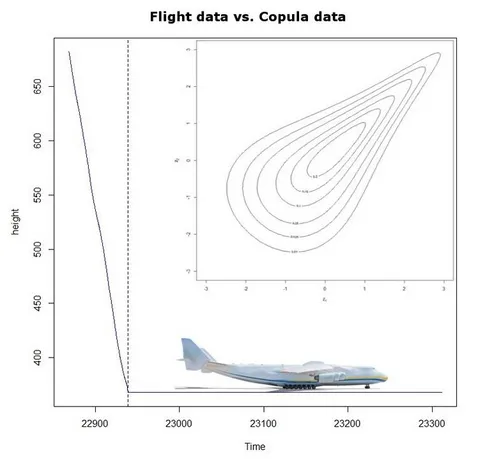
Flight safety analysis via copula state space models
Members: Hassan Alnasser, Ariane Hanebeck, Claudia Czado
Description: Since airlines are required by law to implement a Safety Management System (SMS) for flight operations, each airline must commit to an Acceptable Level of Safety Performance (AloSP). This leads airlines to express the ALoSP in terms of numerical values. Europe’s vision in 2050, for example, defines a minimum safety target of less than one accident per ten million flights. Methods used to analyze flight data, up until recently, have been often simplistic. For example, accident probabilities are computed as the number of accidents divided by the total number of operations. We aim to propose a flexible stochastic approach to characterize temporal and special noise dependence structures obtained from flight data via copula based state space representations. Here, we want to step away from Gaussian dependencies if necessary. The goal is to build a framework that utilizes flight data, while still combining the physical and statistical representation of aircraft motion. Focus will be on accident probabilities as well as the data during take off and the initial climb.

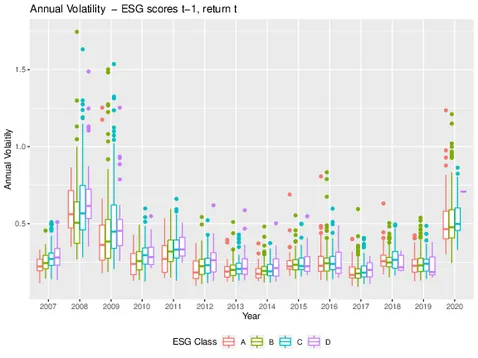
ESG impact on risk
Members: Karoline Bax, Claudia Czado, Sandra Paterlini, Özge Sahin
Description: The availability of environmental, social, and governance (ESG) scores added an additional layer of information for financial practitioners and regulators. However, until today the effect of ESG information on risk-return relationships has not been clearly understood. This research aims to question whether ESG scores can provide relevant information related to (tail)-risk measures and might help in disentangling different sources of risks. It does so, by analyzing the tail dependence structure of companies with a range of ESG scores using high-dimensional copula modeling.
Results: [Article | Preprint | Presentation]
ESGM: ESG scores and the Missing pillar
Members: Özge Sahin, Karoline Bax, Sandra Paterlini, Claudia Czado
Description: The availability of environmental, social, and governance (ESG) scores has skyrocketed in the last decade. However, in recent years, many scholars have found a large discrepancy between ESG scores from different data providers and argued that no clear relationship with standard financial risk measures is prominent. Additionally, the amount of missing information makes the reliability of ESG scores questionable. As a result, the investment decision-making process aiming to create ESG diversification and favorable risk characteristics is even more complex for investors. This research aims to question the effect of the missing data in ESG scores on the risk dependence and the ESG scoring methodology.
Results: [Article1 | Article2]
ClimVine
Members: Marija Tepegjozova, Claudia Czado, Christian Zang, Benjamin Meyer, Anja Rammig
Description: This project aims to quantify the joint probability of drought and spring late-frost risk in the historic domain and identify shifts in this dependency across multiple climate change scenarios to facilitate forest risk assessment. The research is funded by Munich Data Science Instutute, and more information is given on this webpage.
VineGP
Members: Özge Sahin, Claudia Czado, Chris-Carolin Schön
Description: This research aims at improving genomic prediction methods in a multi-population, multi-environment, and multi-trait context in plant breeading to generate crops adapted to future requirements. The research is funded by Munich Data Science Instutute, and more information is given on this webpage.
Results: [Preprint]
Copula state space models with several latent variables
Members: Ariane Hanebeck, Claudia Czado
Description: This project proposes a state space model with several latent variables which uses copulas to get away from the assumption of Gaussian noise. In many applications, it is assumed that the noise follows a Gaussian distribution. However, this assumption is often not met by real datasets. Copulas are an adequate tool to lift the Gaussian assumption and extend state space models to very flexible models. For multiple observations with one latent variable, this model was already considered. The natural extension of this model is to allow for more than one latent variable. The circumstances under which this is solvable have to be identified. A Bayesian approach and MCMC-sampling are used to fit the model.